
🧩今日の学び
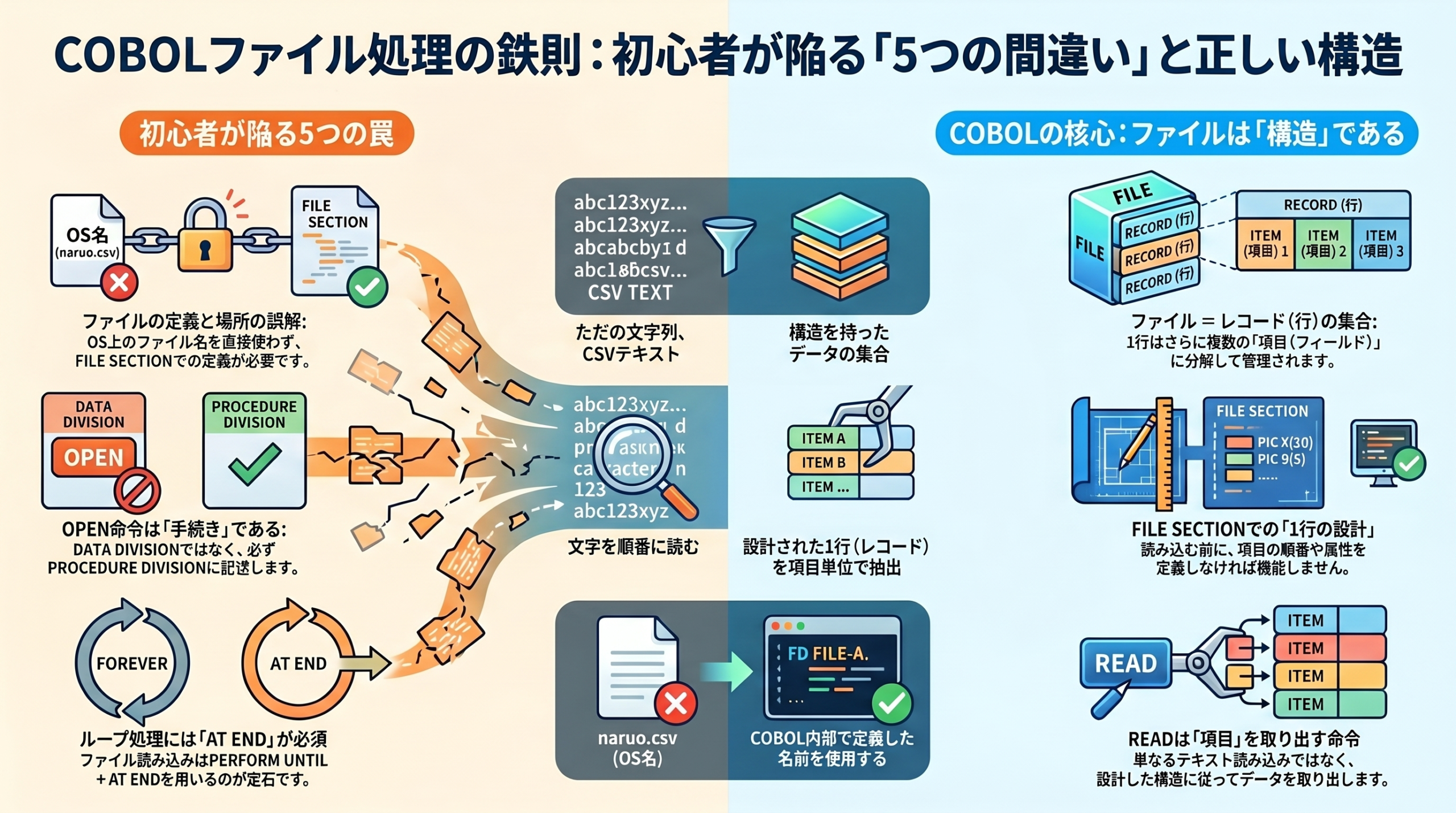
・COBOLではファイルは「文字列」ではなく、レコードと項目に分解された構造として扱う
・READはテキストを読むのではなく、設計された1行(レコード)を項目単位で取り出す命令である
・ファイルを扱うにはFILE SECTIONで「1行の構造」を定義する必要がある
1*>(仮) 2DATA DIVISION. 3WORKING-STORAGE SECTION. 4OPEN naruo.csv. 5 6PROCEDURE DIVISION. 7 8PERFORM VARYING 9READ naruo.csv 10END-PERFORM. 11 12CLOSE naruo.csv. 13STOP RUN.
そのコード 全部ダメだ
係長)これが、お前の仮コードだな。
なるお)えーと、「係長の」じゃないすか…?
係)こんなの書くかよ!
な)「こんなの」言わないで!
係)いいから、何が間違いだと思う?
な)え…と…?
係)全部だな。
な)は!?
子どもを崖下に落とさないで!今どきの子は這い上がって来ないですよ!そこで新たな人生を全うしますよ!
係)するなよ!
ダメだしの始まり
いいか、まずはここ、OPEN naruo.csv
な)ほ?
係)COBOLはファイル名をそのまま使えない。naruo.csvってのは、OSのファイル名だからな。
COBOLはまず「このファイルをどう扱うか」を決める必要がある。
入力なのか、出力なのか、中身はどんな形なのかといったところだ。
な)ふみ…
係)そしてREAD naruo.csvこれもだめだ。
係)READは、ファイル名じゃなくて「ファイルの名前(COBOL側)」を使う。
な)えと…違うんすか?
係)違う。COBOLはファイルを識別できないし、COBOLの名前があるからな。
な)むーん
係)そしてこれ、PERFORM VARYING。
何をVARYINGするつもりだ?カウンタも何もないだろ。そもそもファイル読み込みのループはPERFORM UNTIL+AT ENDが通常だ。
な)良かれと思っての思いやりからです。
思いが重い手編みのセーター的なやつです。
係)思いやりだけで許されるかよ!
な)え!?
係)あとこれ。DATA DIVISIONにOPEN。OPENは処理だ。
な)ほー。あ、といういことはPROCEDUREに書く?
係)そうだ。
な)はーほー?あれ?全部ダメじゃないすか、これ!?
係)だから言っただろ。
な)だから慰めて!
係)うるさい。
整理するとこうだ。
① ファイルを定義してない ② ファイル名そのまま使ってる ③ READの対象が違う ④ ループの条件がない ⑤ OPENの場所がおかしい
ちゃんと壊れてるのが分かる。
な)ちゃんとって…「惜しいけど、ここが悪い」とかのほうが落ち込まないですって
係)わかった、言い直す。
これぞ、だめな見本だ。
な)慰めてって!
係)これを順番に直していくぞ。
な)慰めない!?
READの前に「ファイルの定義」が必要
係)まずは①「ファイルを定義する」からだ。
ファイルは「ただの箱」じゃなく「構造を持ったデータ」だ。
次はそれを作る。FILE SECTIONだ。
な)うー
係)お前の中のこれ。「ファイル=ただのテキスト」この考え方を捨てろ。
な)え、違うんすか!?
係)ファイルを読むってのは、文字を読むんじゃなく、設計した構造を読み取るってことだ。
COBOLにとってファイルは「構造を持ったデータの集合」だからな。
な)はぁ?
係)さっきのCSVの中身
2025-12-31,干し芋,2500
これをお前はただの文字列だと思ってるだろうが、COBOLは違う。
これを、分解してみるとこうなる。
日付:2025-12-31 商品:干し芋 金額:2500
な)ほ?なんか違います?
係)項目(列)で見てるってことだ。
つまりファイルってのは「レコード(1行ずつ)の各項目に分解できるデータの集まり」ってことだ。
な)まためんどくさい言い方を…
係)ファイルの正体はこう分解することができるぞ。
ファイル = レコードの集合
レコード = 項目(フィールド)の集まり
な)なんかわかるようなわからないような…
係)こうするとわかるんじゃないのか?
レコード(1行のまとまり) [a][b][c] 項目 a = 1つの項目 b = 1つの項目 c = 1つの項目
な)うーん、例えば、3つの項目が1行にまとまってれば、それがレコードになるってこと…?
係)そういう意味合いだな。
1行を設計する、それがFILE SECTION
係)そして、ここでやらなければならないこと、それは「1行の設計」ということだ。
な)設計…?
係)項目がどう分かれてるか決めるってことだ。
今回ならこうだな。
日付 商品名 金額
な)あ、項目名?
係)そうだ。それを決めておくってことだ。
それで、それを書く場所がどこだと思う?
な)えーと…データを扱うわけだから、DATA DIVISION?
係)それだと正解とは言えないな。
な)欽ちゃんだったら、審査員を煽って合格点にしてくれますよ?
係)どこに審査員がいるんだよ!
いいかDATA DIVISIONのFILE SECTIONだ。
な)ぐほ!
係)ここでやるのは「1行の形を定義する」ってことになる。
おむすび
な)はー
係)なんか気のない返事だな。
な)いや、なんか意味わからないなーって
係)ま、実際に書いてみるとわかるって話でもあるしな。
な)そんなもんすか?
係)そんなもんだ。
な)オレはそんなヤワじゃないっすよ!
係)なんでそこに反抗するんだよ!
係長のワンポイント
ファイルは「ただの文字列」ではない。
COBOLでは、項目に分解された構造として扱うデータだ。
よくある誤解は「CSVをそのままREADすればいい」だが、それでは動かない。
必ずFILE SECTIONで「1行の形」を設計してから読む必要がある。
その結果、READは文字ではなく“項目単位のデータ”を取り出す。
COBOLはテキストを読む言語ではなく、構造を設計して扱う言語だ。









コメント